This past semester, I took a graduate seminar in Humanities Data Analysis, taught by Professor Ben Schmidt. This post describes my final project. Stay tuned for more fun Bookworm stuff in the next few days (part 2 on Civil War Navies Bookworm is here).
In the 1920s, the United States government decided to create document collections for several of its early naval wars: the Quasi-War with France, the Barbary Wars, and the Civil War (the War of 1812 did not come until much later, for some reason). These document collections, particularly for the Quasi-War and the Barbary Wars, have become the standard resource for any scholar doing work on these wars. My work on the Barbary Wars relies heavily on this document collection. The Barbary Wars collection includes correspondence, journals, official documents such as treaties, crew manifests, other miscellaneous documents, and a few summary documents put together in the 1820s.[ref]U.S. Office of Naval Records and Library, Naval Documents Related to the United States Wars with the Barbary Powers (Washington: U.S. Govt. Print. Off., 1939); digitized at http://www.ibiblio.org/anrs/barbary.html.[/ref]
It’s quite easy to get bogged down in the multiplicity of mundaneness in these documents—every single day’s record of where a ship is and what the weather is like, for instance. It’s also easy to lose sight of the true trajectory of the conflict in the midst of all this seeming banality. Because the documents in the collection are from many authors in conversation with each other, we can sometimes follow the path of these conversations. But there are many concurrent conversations, and often we do not have the full correspondence. How can we make sense of this jumble?
One way we can do this is by divorcing all those words from their immediate context and looking only at who is writing them and when. By tracing words as well as conversations, we may be able to get a fuller picture of how ideas and concepts played out across the entire conflict. I could go through each text searching for mentions of quarantine, supply chains, or diplomacy, and I have done some of that work in the past.[ref]Keyword searches have theoretical problems of their own, as Ted Underwood points out: Ted Underwood, “Theorizing Research Practices We Forgot to Theorize Twenty Years Ago,” Reflections, 2014, https://www.ideals.illinois.edu/handle/2142/48906.[/ref] But that is a painstaking and often fruitless process. Instead of doing all this labor by hand, I can build a tool that will help me do some of this work digitally.
Digital text analysis on historical documents
The bag-of-words approach can be applied to many different types of text analysis, from basic word clouds to more complicated principal component analysis, clustering, and topic modeling. For some of the more complicated ways of analyzing text, the text’s addressability becomes fixed (or at least the levels of addressability become disconnected), leaving the historian unable to properly contextualize the results of the inquiry.[ref]For more on addressability, Michael Witmore, “Text: A Massively Addressable Object,” December 31, 2010, http://winedarksea.org/?p=926.[/ref] For example, clustering using a dendrogram can lead to interesting results, but it’s hard to drill down into the clusters to see why each cluster is constructed in its specific way.
For my work, I need a flexible way to analyze text. My corpus is not particularly large, so it’s easy enough to make arguments about the entire corpus using both traditional and computational methods. But I also do want to be able to make some claims at varying scales, addressing these texts at the word, document, and collection level.[ref]An example of how this might work is Tim Hitchcock, “Historyonics: Big Data for Dead People: Digital Readings and the Conundrums of Positivism,” accessed April 29, 2015, http://historyonics.blogspot.com/2013/12/big-data-for-dead-people-digital.html.[/ref] To get a start on doing some of this analysis, I chose to build a Bookworm, a tool for text analysis similar to the Google n-grams viewer but with the ability to see which text each word appears in, as well as the ability to do some other visualizations besides just the line chart tracking change over time.[ref]More about Bookworm can be found at http://bookworm.culturomics.org/.[/ref] Word-frequency charts are somewhat blunt instruments, but they can also help us approach the data in new ways.[ref]I find helpful Cameron Blevins’s discussion of the value of “sparklines,” which are basically what I’m creating with this Bookworm. Cameron Blevins, “Text Analysis of Martha Ballard’s Diary (Part 3) | Cameron Blevins,” October 19, 2009, http://www.cameronblevins.org/posts/text-analysis-of-martha-ballards-diary-part-3/.[/ref]
What does my Bookworm do?
Superficially, my Bookworm resembles the Google n-grams viewer written about by Michel et al.[ref]Jean-Baptiste Michel et al., “Quantitative Analysis of Culture Using Millions of Digitized Books,” Science 331, no. 6014 (January 14, 2011): 176–82, doi:10.1126/science.1199644.[/ref] However, in important ways, the corpus with which I am working does not resemble the corpora described by Michel et al. The most important difference is the size of the corpus: The Google corpus is more than 500 billion words, where mine is about 1 million. Another significant difference is in the time span of the corpus. The time span of my corpus is about 30 years from the very earliest to the very latest document. The Google Books corpus is, of course, books from every subject. My corpus, by contrast, is about a very specific topic: the Barbary Wars. I’m trying to distant-read a corpus that is able to be completely read in just a few days or weeks. Rather than identifying trends that appear in millions of words of unrelated texts, my Bookworm is meant to help me find trends that get lost in a few thousand very similar texts.

Making the Bookworm
Turning PDFs into text
The six volumes of the Barbary Wars document collection have been digitized by the American Naval Records Society and put online at ibiblio.org. In order to make them usable, I had to first download the volumes and then convert each volume from PDF into a text file. I accomplished this using a Makefile. The Makefile pulled down the PDF of each volume from the web using curl. It then transformed the PDF into raw text using the command-line package pdftotext. Finally, it compiled all 6 volumes’ text files into one big file, since Bookworm prefers one large file with document breaks.[ref]All the code for this project is available on the web at https://github.com/abbymullen/barbary_bookworm.[/ref]
In order to clear out unnecessary clutter, when I did the conversion from PDF to text, I excluded the editors’ introductions, as well as the indexes of each volume. This allowed me to have a text file with only the text that would be useful to analyze in the Bookworm.
Cleaning up the texts
The most sensible unit for analysis of these volumes is the document. Each document in the collection has a header at its beginning (something like “To William Bainbridge from the Secretary of the Navy”), and a citation at its end (something like “[NDA. 1545-54.]”). It made the most sense to use these markers to identify where the documents divided. Because the citation format is always identical, with brackets surrounding text that has to include a limited number of abbreviations, it should have been easy to use a series of regexes to identify where the documents should break. However, this proved more difficult than expected due to OCR problems.
Without question the most problematic part of creating this Bookworm was dealing with the bad OCR. For identifying citations, the abbreviations became mangled; brackets were left off or turned into other characters; and a host of other problems. I ended up writing a large number of convoluted regular expressions to detect these citations, and I know I still did not catch all of the variants.
I used Python to break the large text file into these document chunks. By using a re.sub to add a unique breaking character, I was then able to write a yield function that would yield each document in turn, separate from the others. I still had to clean up the individual documents to clear out the clutter that would throw off any attempts at doing word analysis. Cleanup included removing the running headers and page numbers from each page and removing the citations that I used for delimiting. Again here, OCR and strange line breaks made it impossible to clear out all the clutter, but I think I got most of it.
Here’s an example of the OCR problems I was dealing with. The citation is the text between the brackets at the very end. This particular entry isn’t of much use to me whether I can pull out the citation or not, however, because the text is so poor that almost no words are intelligible.
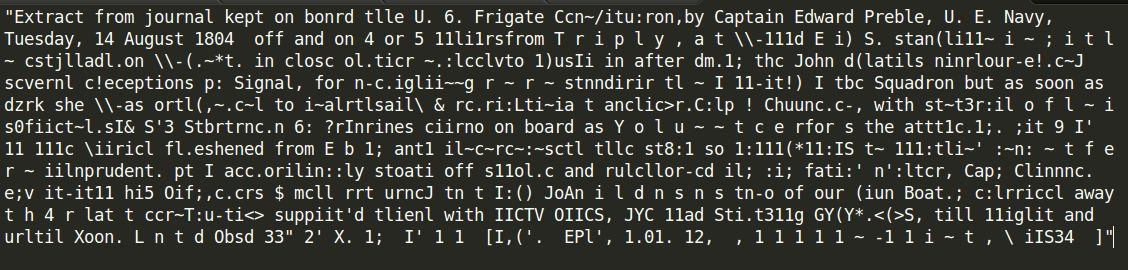
Extracting metadata
Once the documents were broken out individually and the clutter text was cleared out, the next step was to extract metadata. The most important piece of metadata is the date, because without a date, the Bookworm’s linechart interface is basically worthless. However, the date also turned out to be extremely difficult to extract. After trying several different ways to account for all the OCR problems, I eventually had to abandon the plan to get a full date from each document, at least for now. Pulling out just the year was less complicated, so that’s what I ended up doing. Even some of those years are off quite a bit, as the Bookworm demonstrates with the search term “ship,” where spikes occur in the year 1210 and 1601.

I also wanted to extract some data about the author and recipient of each document. Not every document has an author and recipient, but many of the documents are letters or edicts. Many more of them are entries in journals, log books, or diaries, so they have an author. Extracting the letters’ authors and recipients turned out to be the most straightforward of any process in the whole creation of the Bookworm, though even here, the results aren’t perfect. I wrote a regex to extract strings like so: “to [string] from [another string].” To try to eliminate many false hits, I set up some limitations, like a limit of how long each string could be and how many characters in each document were searched (the first 250). This set of limitations didn’t eliminate all false hits, but it did take care of many of them.
To extract author data from the journal entries, I wrote a regex that looked for several OCR variants on the phrase “Extract from the journal of” and returned what came after the phrase. This one was a little more difficult because the editors used a few different formulas to identify journal-like entries, but those differences were fairly easy to overcome.
Building and Reading the Bookworm
Though I did not write the code for Bookworm, it turned out that getting it installed and properly setup on my computer was quite complicated.[ref]Documentation for Bookworm can be found here: http://bookworm-project.github.io/Docs/. For now, my Bookworm is a local installation only; someday it may end up on the web.[/ref] I encountered problems with almost every step, but they were all eventually overcome, with Professor Ben Schmidt’s help.
The Bookworm is searchable using the whole corpus of texts or various subsets based on extracted metadata. Right now the only metadata being extracted are author and recipient, but I hope to expand to more metadata in the future, particularly metadata from log entries.
Bookworm allows the user to look at search results using four metrics: number of words, number of texts, percent of words, percent of texts. In a corpus like mine, these metrics make a big difference, because the earlier years of the data have exponentially fewer texts than the later years. So it’s important to read the results using the proper metric.


Reflections on Process
The process of getting the texts ready to feed into Bookworm was probably the most difficult aspect of the whole project. I learned a great deal about the usefulness and foibles of regular expressions, and I also learned how to chunk large texts into smaller documents that could be more easily managed. My Python skill going into the semester was minimal; after this semester, I think I have a much better handle on how Python in general works. Now I think I have enough of a sense of the syntax and vocabulary of Python that I could probably work up scripts to do other things without feeling completely lost. Similarly, I have been able to use the skills I learned in creating this input file to create other programs that extract data from text files.
Does my Bookworm work?
To be frank, right now, the Bookworm doesn’t really work that well. The OCR problems that plagued the creation of the input file are also problematic for the output. This OCR difficulty makes it hard to judge the Bookworm’s usefulness. It’s not just that spelling variants, or even the poor OCR in places, cause the word counts to be off. The OCR problems have also affected the metadata that is being used to create those trend lines. It’s easy enough to throw out the year 1210 as an incorrect date, but it’s impossible to throw out the year 1803, for instance, without individually checking to make sure it is not the right year, and in many instances, “1803” is being found instead of “1802” or “1805.”
Right now the Bookworm’s subsets of author and recipient are also in pretty bad shape, so their functionality is limited. The way to fix this problem may be to do some data cleanup just like I have had to do with another project I’ve been working on for Viral Texts; it is not technically hard to do, though the regex writing can be time-consuming. But since this is a really helpful feature of the Bookworm, I do want to get it working at maximum efficiency if possible.

If I want to track people, ships, and places, disambiguation also becomes a problem. This is, of course, a problem no matter what kind of text analysis tool you are using. It’s not the problem that Michel et al. have, where words change meaning over the course of time. But words do change meaning depending on place in my data set. The city of Philadelphia is a far cry from the USS Philadelphia, but the two are both important in the story. Similarly, the USS President has nothing to do with the President of the United States, but both matter in the Barbary Wars. The full-text of the individual documents can help us figure out which is which, but it doesn’t give us a way to remove hits that aren’t what we’re actually looking for. (Maybe this feature can be added to Bookworm sometime, though it would only be useful for small Bookworms like mine.)
Bookworm, as with most blunt instruments, is very dull when it comes to detecting small differences in the texts. It’s nice to be able to turn off case sensitivity, but even with that ability, Bookworm can’t detect the difference between the singular and plural of the same word, or variant spellings of the same word. It’s these difficulties that drive me toward topic modeling, though that method has its own host of problems.
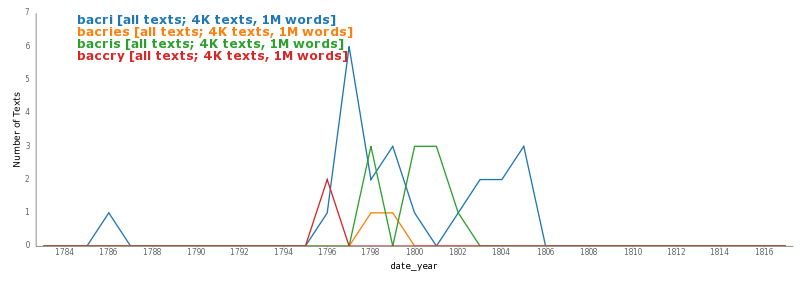
Does it matter that it doesn’t work?
At this point, I have to begin asking: How good is good enough? What is the threshold past which the inaccuracy is too much? For a corpus of millions of books, these legibility issues seem less important, but for a small corpus like mine, every word feels like it counts more. I’m not sure if there’s a metric for how significant OCR errors are, but it seems like my OCR errors are a bigger problem than Google’s are. The date problem is the most worrying, as it messes up the whole point of tracking word changes over time. With such a small corpus, I may just have to go in and do a bit of hand-correction where the problems seem particularly severe, in order to fix these errors.
On the other hand, it’s easy for my eyes to go straight to the entries that aren’t quite right, or to wonder about the words that aren’t getting caught, but the fact is that the vast majority of the text is readable. So once I’ve gotten some of the metadata cleaned up, it probably will not be necessary to do much further work on the body of text itself.
So what now?
So what happens when I get this all cleaned up? Will it still be broken because of the problems I’ve outlined above? Or have I really built something useful? I think I have built something useful. So far in my very basic poking around with the tool, the trends the Bookworm shows are ones that I’ve thought to be true for a while.[ref]Matthew Lincoln addresses the question of actual prior knowledge versus the feeling of prior knowledge in this blog post: Matthew Lincoln, “Confabulation in the Humanities,” March 21, 2015, http://matthewlincoln.net/2015/03/21/confabulation-in-the-humanities.html.[/ref] However, my own intuitive ideas about what’s happening in the Barbary Wars still need to be verified, and in the past I’ve discovered that my intuitive feelings about the history of naval conflicts do not necessarily match the understandings of other naval historians about the same conflicts. So it is helpful to be able to point to something that provides at least some evidence that my conclusions are right—or that challenges them. Beyond that, once I get the other D3 visualizations working, I hope to use those visualizations as another avenue for exploration of the data.
This Bookworm alone is not going to revolutionize my arguments about the logistics of overseas deployment in the Barbary Wars. But it is going to provide some needed evidence for claims about trends across the entire conflict, as well as evidence for change in strategies and rhetoric. In conjunction with other methods, both traditional and digital, I believe this Bookworm can be a significant addition to the methodological approaches I intend to take in my dissertation.
Leave a Reply